
- クローラーはどんな仕組みをしているんだろう?
- クローラー対策はSEOに効果があるの?
- クローラビリティはどうやって高めるの?
SEO対策を勉強していると、「クローラー」「クローリング」という言葉を耳にするでしょう。
クローラーは、世界中のWebサイトのデータを収集しながらページ間を巡回する役割を担っています。
クローラーが収集したデータがあるからこそ、検索エンジンにキーワードを打ち込むと検索結果が表示されています。
つまり、クローラーが自身のサイトに巡回してこなければ、検索エンジンにキーワードを打っても、検索結果に出ることはありません。
今回は、クローラーの特徴を踏まえて、以下の内容について解説をしていきます。
- クローラーがどのように巡回しているのか?などクローラーの仕組み
- クローラーが自身のページに訪れたかを確認する方法
- クローラーに高頻度で巡回してもらうためのSEO対策
特に立ち上げたばかりのWebサイトは、クローラーが訪れていない可能性があるので、この記事をみてクローリング対策しましょう!
それでは、本編をどうぞ!
クローラーとは

クローラーとは、インターネット上にあるWebサイトや画像、地図情報などのあらゆる情報を巡回し、自動的にデータベースを作成するためのプログラムです。「ボット(bot)」や「スパイダー」などとも呼ばれています。
簡単にいえば、インターネット上にある情報を集めてくることを目的としたロボットです。
「這う」という意味を持つクロール(crawl)が語源で、インターネット上にある情報を這うように取得していく様から、クローラーと呼ばれます。
クローラーが自身のサイトに訪れてはじめてデータ登録(インデックス)されるため、クローラーが一度も訪れていないWebサイトは、どれだけSEO対策をしても検索エンジンに表示されません。
クローラーは定期的にサイトを巡回して情報を更新していますが、 巡回頻度はサイトの更新頻度などにより異なります。
クローラーの仕組み
クローラーの種類
クローラーは検索エンジンごとに種類が違い、GoogleならGooglebot、BingならBingbot、中国のBaidu(百度)はBaiduspiderというクローラーを使っています。その他にもNaverのYetibot、ApacheのManifoldCFなどのクローラーがあります。
尚、Yahoo JapanはGoogleの検索エンジンを使用しているので、表向きは違いますが、裏側のクロールの仕組みは同じです。
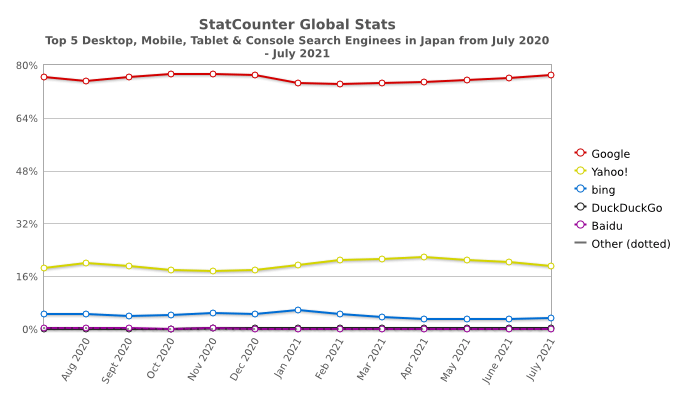
国内の検索エンジンのシェア率は以下の通りで、GoogleとYahoo!で約95%のシェアがあります。
- Google:75.48%
- Yahoo!:19.48%
- Bing:4.59%
- DuckDuckGo:0.22%
- Baidu:0.11%
- YANDEX:0.04%
Yahoo!はGoogleの検索エンジンを使っていますが、GoogleとYahoo!では若干検索結果が異なります。
理由としては、各社のクロールのタイミングが違うこと、Yahoo!の場合は「ヤフオク!」「Yahoo!ショッピング」「Yahoo!知恵袋」など自社サービスの上位表示を優先すること、Googleは検索ユーザー個人にあわせた「パーソナライズド検索」を取り入れているため検索結果が個々で変わることなどがあります。
クローラーの巡回方法
クローラーは、ロボットが「HTTP/HTTPSプロトコル」をたどって、自動的にWebサイトを巡回していきます。
基本的には内部リンクや外部リンク・XMLサイトマップ・robots.txtなどを参考にして、Webサイトをクローリングしています。
| 内部リンク・外部リンク | ページに貼ってあるリンク。href 属性が指定された <a> タグのリンクのみクロールできる。 |
| XLMサイトマップ | Webサイトの全ページへのリンクをひとまとめにして掲載しているページ。デパートや大型ショッピングモールにあるフロアマップのようなもの。 |
| robots.txt | 収集されたくないコンテンツを検索エンジンによってクロールされないよう制御するファイル。 |
クローリングを行いながら、以下のようなファイルを収集し、結果をデータベースに登録していきます。
- HTML
- テキストファイル
- CSSファイル
- JavaScriptファイル
- 画像(GIF/JPEG/PNG/WebP/SVG)
- 動画(MP4/WebMなど)
- オフィス文書(Word/Excel/PowerPoint)
クローラーは画像や文書ファイルを取得しますが、画像ファイルの中にあるテキスト情報等は読み込めません。なので、どんな画像なのか代替テキスト(Altタグ)を設定する必要があります。
クローラーが巡回したページの確認方法
クローラーが循環しなければサイトやページが検索結果に表示されません。つまり、せっかく書いた記事も公開されません。
新たにサイトやページを作成した場合は、クローラーが巡回し、正常にインデックスされているか必ず確認しましょう。
ここでは、サーチコンソールと「site:」で簡単に確認する方法を解説します。
Googleサーチコンソールを使用する方法
サーチコンソールにログイン後、サイト上部にある検索窓に検索したいURLを入力します。
サーチコンソールの登録がまだ済んでいない方は、「Googleサーチコンソールの登録方法を解説!検索結果がわかる!」の記事をご覧ください。
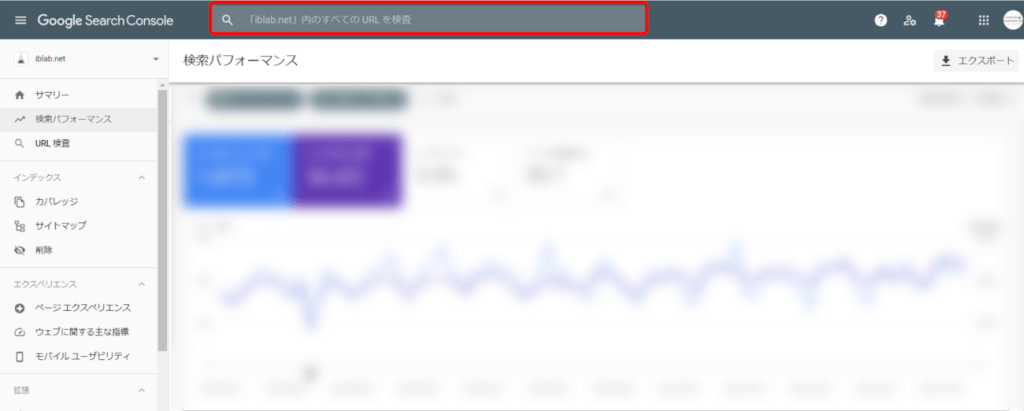
クローラーが巡回して、インデックスされていると、以下のように「URLはGoogleに登録されています」と表示されます。
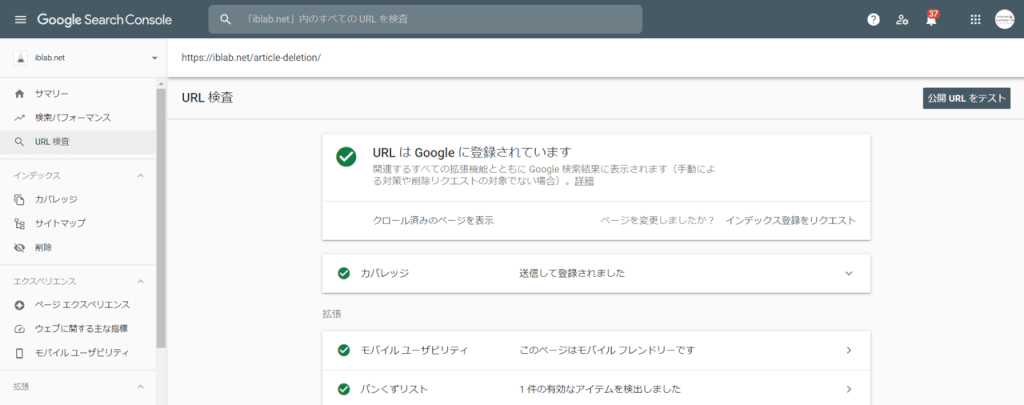
インデックスされていない場合は、以下のように「URLがGoogleに登録されていません」と表示されます。
site: で検索する
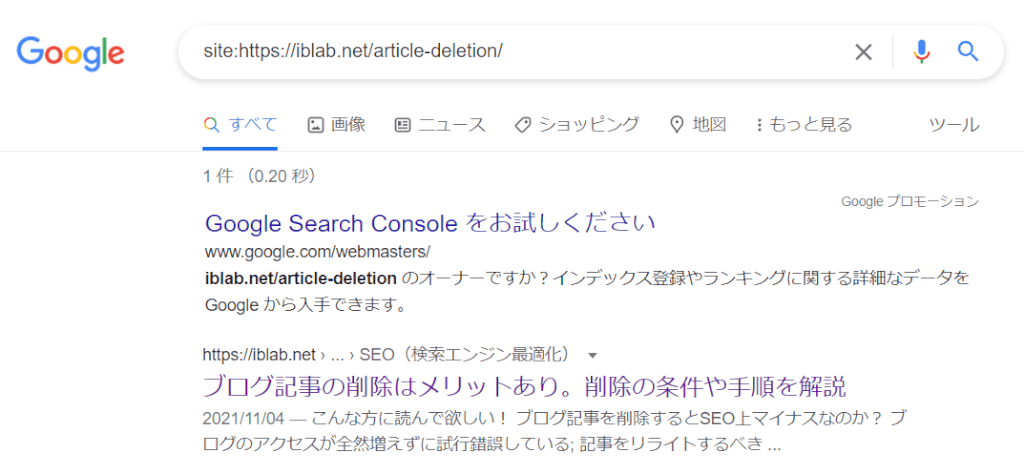
サーチコンソールよりも気軽に調べる方法は、Googleの検索窓に「site:サイトのURL」を入力する方法です。
クローラーが巡回して、インデックスされていれば、以下のように記事が表示されます。
クローラーのSEO対策
クローラーに検索されやすくするために、クローラビリティの最適化が必要です。
クローラビリティとは、クローラーによるページの見つけやすさ、コンテンツの内容の理解のしやすさを指し、クローラビリティを最適化することで、自ページが検索エンジンに発見されやすくなります。
クローラビリティを高めると、新規ページが発見されやすくなるだけでなく、未インデックスページを少なくしたり、WEBページの評価がいち早く検索エンジンに反映されやすくなるためSEO効果があります。
XMLサイトマップを登録する
クローラーは、内部リンクや外部リンク・XMLサイトマップ・robots.txtを辿ってサイトを巡回するため、外部リンクもほとんど貼られていない作ったばかりのサイトは、クローラーに気付かれません。
サイトを公開したら、まずはクローラーにサイトの存在を知らせるためにXMLサイトマップをGoogleに送信します。
もっとも簡単なやり方は、「Google XML Sitemaps」プラグインを使い、自動生成されたXMLサイトマップを、サーチコンソールを通じて送信する手順です。
詳しいやり方は、「Google XML Sitemapsの設定方法を解説!【WordPress初心者向け】」で解説しています。
更新頻度を上げる
クローラビリティを高める最良の方法は、サイトの更新頻度を高める方法です。
クロールする度にサイトに新しいコンテンツができていたり、過去のコンテンツがリライトされるなど、サイトの更新頻度が高ければクローラーの訪問頻度は上がります。
ブログの場合、毎日更新する必要がありませんが、クローラーが高巡回させるには週2・3更新が望ましいです。
とはいえ、日付だけを更新したり、パーマリンク、画像の差し替え、若干のてにをは修正などの質の低いリライトや、質の低い新規ページ作成などはクローラビリティを高める要因にはなりません。
むしろ、質の低いリライトや新規ページの作成を繰り返すと、SEO評価を下げる恐れがあるので注意しましょう。
サイトの更新頻度については「ブログの毎日更新は辞めるべき!その理由と最適な更新頻度について解説」で解説しています。
重複コンテンツの削除
重複コンテンツと判断されると、インデックスされません。
重複コンテンツは、サーチコンソールの「カバレッジ→除外」メニューで調べることができます。
重複コンテンツがあると、以下のようなページがあるので、重複しているコンテンツを見つけて修正しましょう。

重複コンテンツは基本的にぺナルティ要素ではありませんが、著作権にかかわるようなコンテンツはペナルティの対象になります。
また、あまりにも重複コンテンツが多い場合や、重複コンテンツが長く改善されない場合は、サイト全体のSEO評価が下がる可能性があります。
- 他のサイトのコンテンツをコピーし、独自のコンテンツや付加価値を加えることなく転載しているサイト
- 他のサイトのコンテンツをコピーし、(語句を類義語に置き換えたり自動化された手法を使用したりして)若干の修正を加えた上で転載しているサイト
- 何らかの独自の体系付けやユーザーへの利便性を提供することなく他のサイトからのコンテンツ フィードをそのまま掲載しているサイト
- ユーザーに実質的な付加価値を提供することなく、他のサイトの動画、画像、その他のメディアなどのコンテンツを埋め込んだだけのサイト
URLの階層は3段までにする
クローラーは、階層の浅いページから順に優先的にクロールするため、すべてのページにトップページから2クリックで行けるように設計することが大切です。
クローラーが巡回しにくい構造のサイトになっている場合は、構造を見直すといいでしょう。
「カテゴリリンク」「パンくずリスト」を表示したり、サイドバーから網羅的にページに辿り着けるように設計することも非常に重要です。
検索エンジン向けのXMLサイトマップとは別に、検索ユーザー向けにHTMLサイトマップのページを作成するのもいいでしょう。
リンクに意味を持たせる
クローラー対策で、内部リンクや外部リンクを貼ることは重要ですが、アンカーテキストに対策したいキーワードを必ず入れましょう。
アンカーテキストとは、実際にリンクを貼る文字列です。よく見るのが「○○の詳細はこちら」のように記述し、「こちら」だけにアンカーテキストにしているパターン。
これではリンク先のページのキーワードがGoogleに伝わらず、質の低いリンクと評価を下げてしまいます。
この場合は、意味のある「○○」にアンカーテキストを貼るようにしましょう。

URLをそのまま載せてリンクを貼るのも、質が低いリンクと評価されます。
まとめ
クローラーは、インターネット上にある情報を集めてくることを目的としたロボットで、巡回頻度はサイトの更新頻度などにより高めることができます。
巡回は、基本的に内部リンクや外部リンク・XMLサイトマップ・robots.txtなどをもとに辿られるため、リンクを張り巡らせることや、XLMサイトマップをサーチコンソールに送信することは必須の対策といえます。
クローラビリティを高めるには、更新頻度を高めるのが重要ですが質の低い更新はSEO上マイナスになる可能性もあるので、しっかりと価値のあるコンテンツづくりを心掛けましょう。